JetBrains AI クレジット消費問題に対する実践的解決策 LiteLLMを活用しGeminiやChatGPTなどの外部LLMを統合する方法
目次
- 1. はじめに:JetBrains AI クレジット消費問題
- 2. 解決策:なぜLiteLLMが最適なのか
- 3. LiteLLMのセットアップ手順
- 4. JetBrains IDEでの設定と動作確認
- 5. まとめ
この記事のポイント
- JetBrains AI クレジット消費が速い問題の代替案を提示します。
- ローカルPCのスペックに依存せず、GeminiやChatGPTなどの最新LLMをIDEで利用する方法を解説します。
- プロキシツール「LiteLLM」を使い、外部LLM APIをJetBrains AI Assistantに接続する具体的な手順を紹介します。
1. はじめに:JetBrains AI クレジット消費問題
私は、普段からJetBrainsのIDEを利用しています。他の多くのエディタと同様に、JetBrains製品にもAI関連機能が組み込まれ、快適に利用していました。
しかし2025年6月頃、JetBrainsからAI関連のライセンス変更やクレジット制に関するアップデートが発表されました。
2025年4月にリリースされた JetBrains IDE バージョン 2025.1 では、こちらの発表にあるように AI 関連で大きなアップデートがありました。
このブログ記事では、コーディング AI エージェント Junie や JetBrains AI Assistant に含まれる無制限のクラウドーコード補完など技術的な変更点と新料金プラン、および、良くある質問についてまとめました(2025年6月公開、2025年8月更新) 。
私は、2015年からAll Products Packを契約しており、AI Assistantの利用開始後はAI Ultimateプランを契約しています。
ある時、IDEのウィジェットでAI クレジットの消費量を確認したところ、最近のアップデートの影響か、消費スピードが以前より明らかに速くなっていることに気づきました。アップデートによる消費量の増加は理解できるものの、このままでは継続利用が難しいと判断し、代替案を模索することにしました。
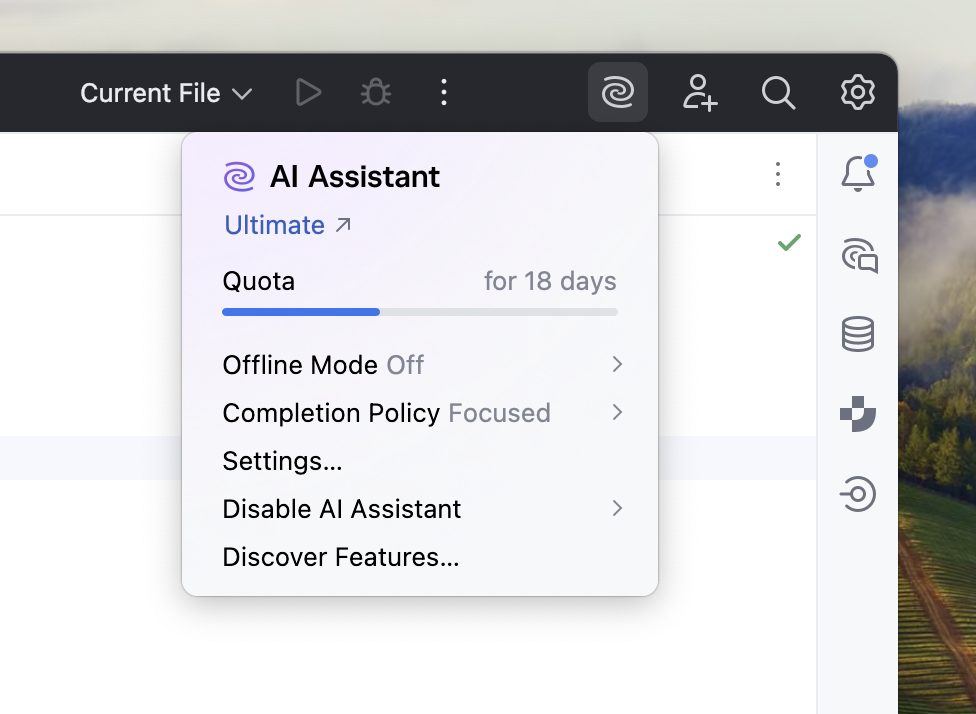
2. 解決策:なぜLiteLLMが最適なのか
JetBrainsのドキュメントを調べると、AI Assistantがサードパーティ製のモデルやローカルで動作するLLMをサポートしていることがわかりました。これにより、AI クレジット消費を回避する道筋が見えてきました。
JetBrains AI の新プランでは、OpenAI, Google, Anthropic 等のサードパーティクラウド LLM を使用する機能は週または月ごとの Quota/クォータ制(利用可能なクレジット量に対する制限 詳細はこちら)の対象となっており、利用する LLM モデルや入力コンテキスト量、出力量に応じてクレジットを消費する仕組みとなっています。
一方で、ローカル LLM を使用する場合は、AI Free プランの導入により、有償プランがなくても、AI 機能が利用可能になりました。
By default, AI Assistant provides access to a predefined set of cloud-based models that are used for AI-related features.
However, you can configure it to use custom local models provided by third parties.
デフォルトでは、AI AssistantはAI関連機能に使用される事前定義されたクラウドベースのモデル群へのアクセスを提供します。
ただし、サードパーティが提供するカスタムローカルモデルを使用するように設定することも可能です。
代替案として、大きく2つの方法が考えられます。
方法1:Ollamaで完全なローカル環境を構築する
一つは、Ollamaのようなツールを使って、自身のPC上で言語モデルを直接実行する方法です。これは完全なオフライン環境を構築できるため、セキュリティ面やコスト面で大きなメリットがあります。
ollama/ollama: Get up and running with OpenAI gpt-oss, DeepSeek-R1, Gemma 3 and other models.
メリット
- 完全なオフライン環境で動作し、セキュリティが高い(プライベートなアクセス)
- APIコストがかからない
デメリット
- 高いマシンスペック(特にVRAM)が必須
- PCのディスク容量を大きく消費する
- モデルの実行中はPCの負荷が常に高くなる
感想
実際に試したところ、PCの負荷が常に高くなるため、開発作業との両立が難しいと感じました。同様のツールである llama.cpp も試しましたが、結論は同じでした。
方法2:LiteLLMで外部APIをプロキシする
もう一つの方法が、本記事で詳しく解説するアプローチです。これは、ローカルにプロキシサーバーを立て、そこからGeminiやChatGPTといった外部のLLM APIを呼び出すことで、マシンスペックに依存せず、かつJetBrains AI クレジットを消費しないハイブリッドな方法です。
様々なLLM APIのインターフェースを統一したいというニーズは普遍的であり、それを解決するツールが存在するはずだと考え調査したところ、「LiteLLM」を見つけました。
LiteLLMは、GeminiやCloudflare Workers AIなど100以上のLLM APIを、OpenAI API互換の形式に変換してくれるプロキシサーバーです。これにより、JetBrains IDEのAI Assistantから、あたかもローカルのOpenAIモデルを呼び出すかのように、多種多様な外部LLMを利用できるようになります。
メリット
- セットアップが非常に簡単
- ローカルPCのマシンスペックをほとんど要求しない
- Gemini、ChatGPT、Claudeなど多くのモデルを自由に試せる
- モデルのダウンロードが不要で、すぐに利用を開始できる
デメリット
- 利用するLLMに応じたAPIコストがかかる
- 利用中はローカルでプロキシサーバーを起動しておく必要がある
感想
モデルのダウンロードが不要で、マシンスペックに依存しない点は大きな利点です。簡単な設定ファイル一つで多くのモデルを切り替えられるため、非常に柔軟な運用が可能です。
3. LiteLLMのセットアップ手順
LiteLLMの設定は非常に簡単です。ここではPythonのパッケージインストーラuvを使いますが、pipでも同様にインストール可能です。
インストール
# litellmとプロキシ機能に必要なパッケージをインストール
uv pip install litellm 'litellm[proxy]'設定ファイル(config.yaml)の作成
プロジェクトのルートにconfig.yamlというファイルを作成し、使用したいモデルを定義します。
# config.yaml
# モデルリストを定義
model_list:
# openai
- model_name: gpt-5-nano
litellm_params:
model: openai/gpt-5-nano
api_key: os.environ/OPENAI_API_KEY
# google
- model_name: gemini-2.5-flash-lite
litellm_params:
model: gemini/gemini-2.5-flash-lite
api_key: os.environ/GEMINI_API_KEY
- model_name: gemini-2.5-flash
litellm_params:
model: gemini/gemini-2.5-flash
api_key: os.environ/GEMINI_API_KEY
- model_name: gemini-2.5-pro
litellm_params:
model: gemini/gemini-2.5-pro
api_key: os.environ/GEMINI_API_KEY
# cloudflare
- model_name: llama-4-scout-17b-16e-instruct
litellm_params:
model: cloudflare/@cf/meta/llama-4-scout-17b-16e-instruct
# <YOUR_COUDFLARE_ACCOUNT_ID> をご自身のCloudflareアカウントIDに置き換えてください
api_base: "https://api.cloudflare.com/client/v4/accounts/<YOUR_COUDFLARE_ACCOUNT_ID>/ai/run/"
api_key: os.environ/CLOUDFLARE_API_KEY
drop_params: true
modify_params: true
max_tokens: 4096 # 例として大きめの値を設定
# 必要に応じて設定を追加
litellm_settings:
debug: true # デバッグログを有効にする
timeout: 600 # 秒単位でタイムアウトを指定 (例: 10分)
プロキシサーバーの起動
必要なAPIキーを環境変数として設定し、LiteLLMを起動します。
export GEMINI_API_KEY="sk-..."
export OPENAI_API_KEY="sk-..."
export CLOUDFLARE_API_KEY="your-api-token"
litellm --config config.yaml成功すると、http://0.0.0.0:4000でサーバーが起動します。
(litellm-app-uf9) MacBook-Pro-14:litellm-app-uf9 teruhiro$ litellm --config config.yaml
INFO: Uvicorn running on http://0.0.0.0:4000 (Press CTRL+C to quit)
INFO: Started parent process [3009]
INFO: Started server process [3019]
INFO: Waiting for application startup.
██╗ ██╗████████╗███████╗██╗ ██╗ ███╗ ███╗
██║ ██║╚══██╔══╝██╔════╝██║ ██║ ████╗ ████║
██║ ██║ ██║ █████╗ ██║ ██║ ██╔████╔██║
██║ ██║ ██║ ██╔══╝ ██║ ██║ ██║╚██╔╝██║
███████╗██║ ██║ ███████╗███████╗███████╗██║ ╚═╝ ██║
╚══════╝╚═╝ ╚═╝ ╚══════╝╚══════╝╚══════╝╚═╝ ╚═╝
#------------------------------------------------------------#
# #
# 'It would help me if you could add...' #
# https://github.com/BerriAI/litellm/issues/new #
# #
#------------------------------------------------------------#
Thank you for using LiteLLM! - Krrish & Ishaan
Give Feedback / Get Help: https://github.com/BerriAI/litellm/issues/new
LiteLLM: Proxy initialized with Config, Set models:
gpt-5-nano
gemini-2.5-flash-lite
gemini-2.5-flash
gemini-2.5-pro
INFO: Application startup complete.動作テスト
サーバーが正常に動作しているか、curlコマンドで確認します。
curl http://localhost:4000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-2.5-flash-lite",
"messages": [
{
"role": "user",
"content": "日本で一番高い山は?"
}
]
}'以下のようなJSONレスポンスが返ってくれば成功です。
{
"id": "38LAaLTDPMLRz7IPgZyb6Q0",
"created": 1757463263,
"model": "gemini-2.5-flash-lite",
"object": "chat.completion",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "日本で一番高い山は **富士山** です。\n\n標高は **3776メートル** です。",
"role": "assistant",
"thinking_blocks": []
}
}
],
"usage": {
"completion_tokens": 25,
"prompt_tokens": 8,
"total_tokens": 33,
"prompt_tokens_details": {
"text_tokens": 8
}
},
"vertex_ai_grounding_metadata": [],
"vertex_ai_url_context_metadata": [],
"vertex_ai_safety_results": [],
"vertex_ai_citation_metadata": []
}4. JetBrains IDEでの設定と動作確認
ローカルでプロキシサーバーが起動した状態で、JetBrains IDEの設定を行います。
AI Assistantにローカルモデルを設定
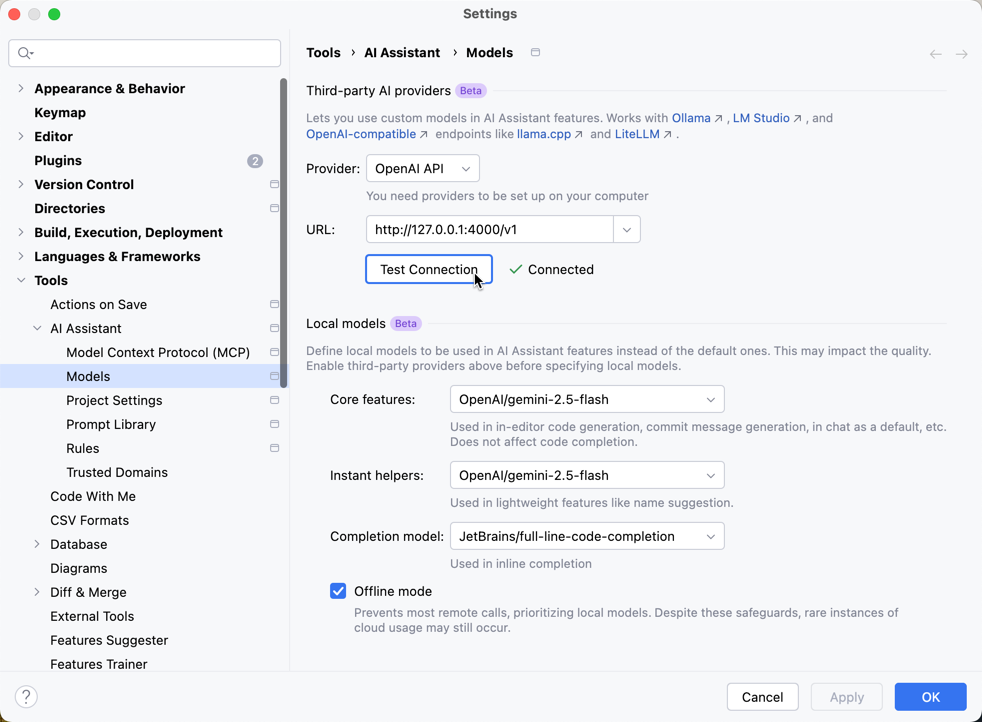
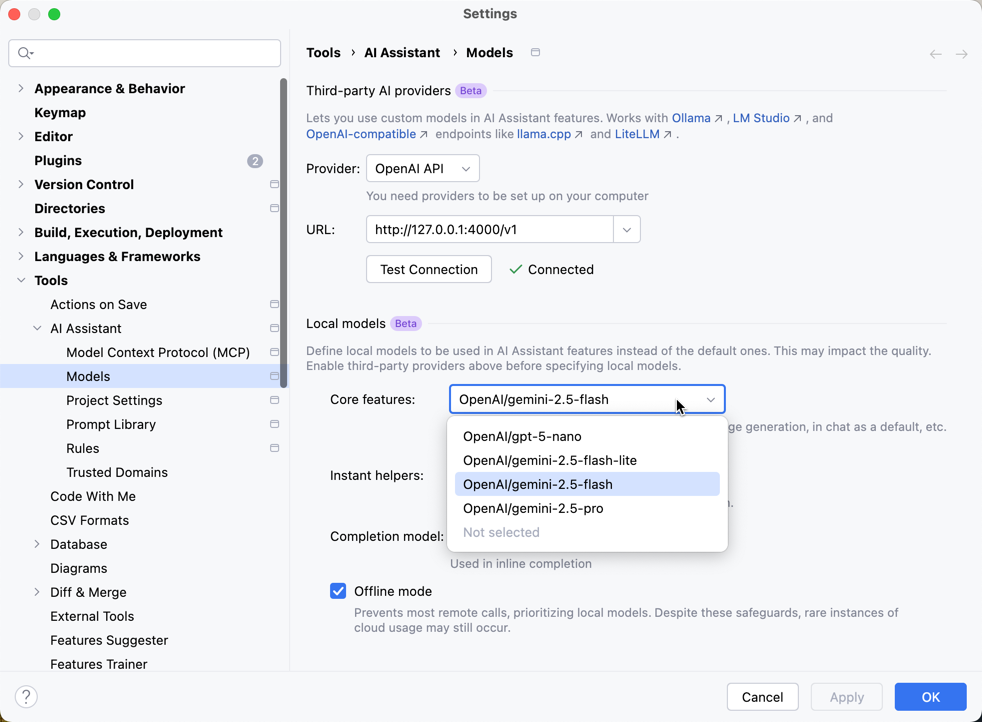
IDEの 設定 > AI Assistant > Models を開きます。
- Provider:
OpenAI API - URL:
http://localhost:4000/v1
「Test Connection」をクリックして接続が成功することを確認します。
AI Assistantをオフラインモードに変更
次に、AI Assistantのウィジェットを開き、メニューから「Offline Mode」を有効にします。これにより、JetBrainsのクラウドサービスを経由せず、先ほど設定したローカルのエンドポイントのみが使用されるようになります。
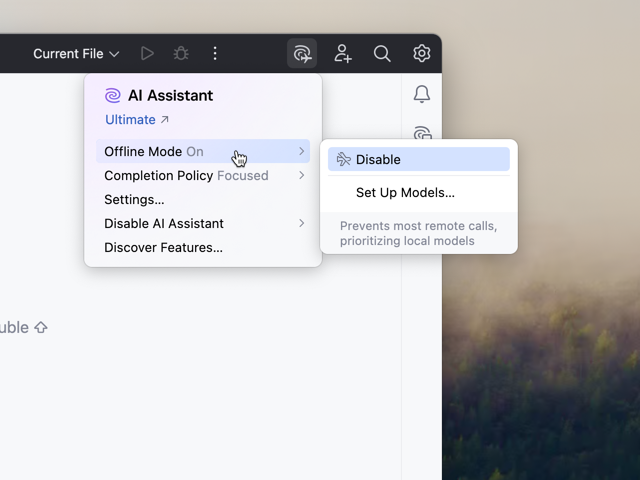
オフラインモードを有効にすると、チャットウィンドウのモデル選択肢がローカルで設定したものだけに変わります。
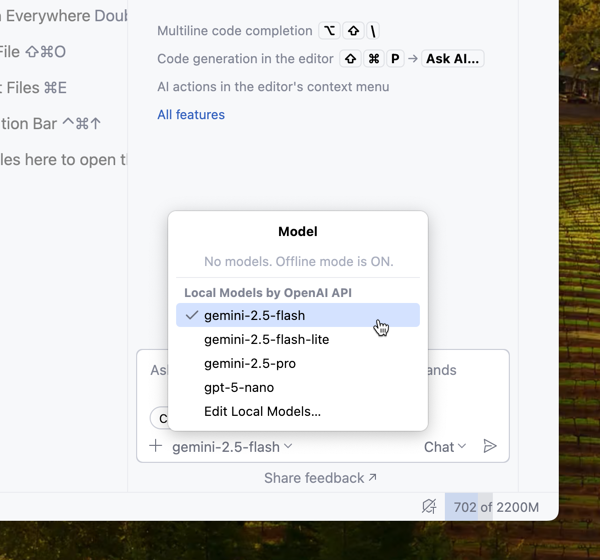
動作確認
実際にいくつかの機能で動作を確認します。
チャット機能でのテスト
チャットで質問を投げかけると、LiteLLMのターミナルにリクエストが記録され、IDE上にモデルからの応答が正しく表示されます。
コミットメッセージの下書き作成のテスト
バージョン管理ツールでコミットメッセージを生成する際も、事前に選択したモデル(この例では gemini-2.5-flash)が使用され、差分に基づいたメッセージが作成されます。
5. まとめ
JetBrains AI クレジット消費問題を回避するため、LiteLLMを用いて外部のLLM APIをローカルプロキシ経由で利用する方法を紹介しました。
このアプローチにより、JetBrains AI クレジット消費を気にすることなく、GeminiやChatGPTといった好みの最新LLMをIDEに統合できます。PCのスペックに依存せず、利用するモデルを柔軟にコントロールできる点が最大のメリットです。JetBrainsのAI Assistantをより自由に、そして経済的に活用したい方は、ぜひ試してみてください。
